Le guide ultime pour commencer votre podcast
Posté le 15 Mars 2021 dans Technologie Science Créativité Productivité
Les podcasts sont de plus en plus nombreux de nos jours. L’idée est de pouvoir parler librement de ce que l’on souhaite et de diffuser le contenu sur Internet. J’ai décidé de lancer le mien pour passer de bons moments avec mes invités et faire rire les auditeurs, lancer un projet personnel, m’intéresser au matériel du son et améliorer mon aisance à l’oral. Nombre de personnes sont tentées de commencer leur propre podcast car cela ne nécessite pas énormément d’investissement. Pourtant, il faut quand même connaître quelques notions de base. Avant de me lancer dans un nouveau domaine j’aime apprendre et comprendre par moi-même comment il fonctionne et ne pas juste suivre les tendances. Quand j’ai commencé à chercher des réponses à mes questions, j’avais du mal à trouver du contenu réellement précis, c’est la raison pour laquelle j’ai décidé d’écrire cet article, en espérant qu’il puisse vous aider au maximum. Si on rentre dans les détails techniques, ça peut vite devenir très complexe et ce n’est pas mon but ici. Néanmoins si vous êtes vraiment intéressé par le sujet je mets quelques liens vers des ressources techniques pointues en fin d’article. Je mets aussi un petit glossaire de certains termes qui me paraissent importants à connaître. Même si vous pouvez assez facilement évoluer vers le “plus”, réfléchissez au nombre de personnes qui interviendront simultanément dans une émission. J’ai fait le choix d’avoir maximum 4 invités, ce qui complique pas mal les choses. Cet article est donc plutôt destiné à ceux qui souhaitent inviter plusieurs personnes en même temps. Si vous êtes dans le même cas que moi et que vous aimez comprendre des choses, cet article devrait vous intéresser.
Pour structurer l’article je vais suivre la chaîne du son.
La Voix
Tout commence avec votre voix. Lorsque vous parlez, vos cordes vocales se mettent en mouvement ce qui fait vibrer l’air. La résultante est une onde sonore qui se propage dans toutes les directions à environ 340m/s. On peut modéliser l’onde par une courbe de fréquence qui ressemble à ceci :

De plus, on peut relier la fréquence à la période de l’onde via la formule f=1/T où f représente la fréquence en Hz et T la période de l’onde. La période est l’intervalle de temps d’un seul motif élémentaire. Plus la fréquence est élevée (période courte) et plus le son sera aigu, à l’inverse une fréquence basse (période longue) produira un son grave. Donc quand on parle de “hauts” on parle en réalité des aigus et quand on dit “dans les bas” ou “des basses” il s’agit des graves. Entre les aigus et les graves on retrouve les médiums. C’est principalement dans cette gamme de fréquences que se situe la voix. On peut diviser les médiums en bas-médiums et en hauts-médiums.
Le microphone
Il nous faut maintenant un dispositif pour capter la voix émise. Nos oreilles sont un bon exemple de capteur. Dans celle-ci se trouve le tympan, une fine membrane qui vibre en fonction des fréquences présentes dans l’air avoisinant. Comme chaque fréquence est unique, le tympan vibre de manière unique en fonction de l’onde qu’il reçoit. Il envoie alors un signal électrique via les nerfs à notre cerveau qui interprète le signal en son. La gamme de fréquence audible par l’oreille humaine se situe entre 16Hz et 20kHz et varie un petit peu (surtout dans les aigus) selon l’âge.
Un micro fonctionne globalement de la même manière que notre oreille. Il comporte une membrane qui vibre sous l’effet des ondes et son transducteur transforme cette vibration en signal électrique alors envoyé à travers des câbles jusqu’au dispositif enregistreur. Il existe plusieurs types de micros. Dynamique, à ruban, statique, stéréo, de contact, à effet de surface… Les deux principales catégories sont les micros dynamiques et les micros statiques.
Le micro dynamique
C’est le micro que tout le monde connaît, utilisé sur scène dans les concerts, à la télé ou dehors par les journalistes. L’avantage de ce type de micro est sa robustesse, son prix et sa facilité d’utilisation. Le micro dynamique s’utilise aussi à la radio et donc en podcast. Après avoir débuté avec un micro statique puis un dynamique, je vous conseille vivement d’acheter uniquement des micros dynamiques. Notamment si vous faites un podcast à plusieurs et/ou dans un environnement non insonorisé. Ils sont cependant limités dans les aigus.
Le micro statique
Le micro statique se divise en plusieurs types. A électret, à lampe, à transistor, à grande ou petite membrane. Ce type de micro est principalement utilisé en studio d’enregistrement du fait de sa grande sensibilité. Qui dit sensibilité plus élevée dit sensible aux bruits parasites. Un micro statique est donc destiné à un environnement calme et insonorisé comme un studio, sinon il captera tous les petits bruits. Selon moi, la seule raison d’utiliser un micro statique pour un podcast est si vous êtes seul à parler. Si vous utilisez plusieurs micros statiques en même temps pour un podcast, c’est la galère au montage. Il y a plein de petites subtilités que je n’aborderai pas ici.
Indépendamment du type, chaque micro présente des caractéristiques intrinsèques. Les plus importantes seront :
- sa sensibilité, donnée en mV/Pa ou en dB. Elle définit la valeur de courant émise par le micro. Si elle est supérieure à 8 mV/Pa, vous ne devriez pas avoir de problème. Sinon, vous trouverez plus d’infos dans le prochain paragraphe.
- sa directivité, qui indique comment le micro capte les sons. On retrouve le cardioïde et ses dérivés élargi, super et hyper, l’omnidirectionnel et le bidirectionnel. Pour un podcast, privilégiez le cardioïde. Il captera bien votre voix et beaucoup moins celle des autres interlocuteurs s’ils sont situés derrière votre micro, ce qui facilite le montage.
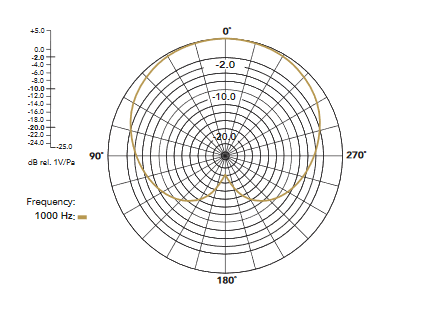
- son impédance, c’est-à-dire la capacité du micro à s’opposer au passage du courant électrique. Un bon micro a une impédance inférieure à 1 kOhm. Idéalement, l’impédance d’entrée de votre carte son devrait être au moins deux fois supérieure à celle du micro. Avec du matériel de bonne qualité même en entrée de gamme, cette condition est souvent respectée.
- sa courbe de réponse en fréquence qui renseigne sur la gamme de fréquence que le micro peut enregistrer. C’est ce qui rend chaque micro unique. Une analogie intéressante serait l’objectif d’une caméra. Lorsque vous changez l’objectif c’est comme si vous aviez une autre caméra. La courbe n’est pas parfaitement plate, elle présente des bosses et des creux en fonction des fréquences mises en avant ou en retrait. Théoriquement cela est censé nous aiguiller dans le choix du micro en fonction de l’application voulue mais ces courbes de réponse en fréquence sont rarement fiables car les constructeurs masquent les imperfections et ne donnent pas de détails sur les conditions dans lesquelles ont été réalisés leurs tests. Il est préférable d’écouter un micro avant de l’acheter même si je suis conscient que ce n’est pas toujours possible.
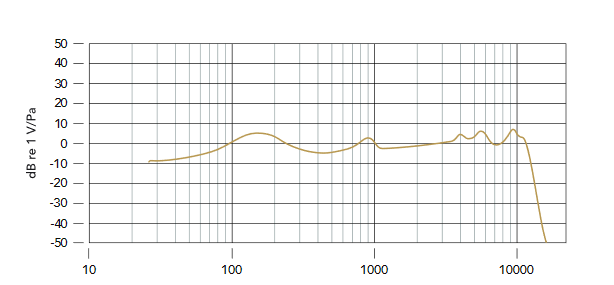
Voici un exemple de caractéristiques que vous retrouvez pour un micro (ici il s’agit du RODE Podmic que j’utilise) :

Pensez à ajouter un filtre anti-pop ou une bonnette. Cet accessoire permet de réduire les plosives, c’est-à-dire les forts déplacements d’air provoqués par les consonnes telles que “p”, “b” ou “t”. Ces plosives saturent la membrane du micro ce qui se traduit par un son désagréable. Il existe donc 2 solutions qui ont chacune leurs avantages et inconvénients. Le filtre pop est constitué d’une fine gaze tendue sur un support circulaire. Si vous êtes adeptes du DIY vous pouvez en fabriquer vous-même avec un collant. Vous trouverez plusieurs tutos sur Internet. L’inconvénient du filtre pop est de masquer la vue de l’interlocuteur ce qui est vite énervant.
La mousse qui compose une bonnette est constituée de milliers de petits trous qui absorbent et diffusent le flux d’air avant d’arriver sur la membrane. Avec certaines bonnettes, les aigus sont atténués ce qui rend un son plus “chaud” donc chaleureux et ténu mais ce n’est pas forcément un effet désiré. La bonnette est plutôt utilisée en extérieur pour pallier le bruit du vent dans le micro mais on la retrouve dans les studios de radio et donc pour les podcasts. Ce n’est pas toujours esthétique mais cela permet aussi de protéger le micro des petites agressions comme les postillons ou la poussière et des petits bruits de la pièce. La mousse a tendance à se détériorer au fil du temps et à se salir. Il faut donc la laver de temps en temps ou la changer.


Comment placer son micro ?
Pour obtenir le meilleur son possible, 2 critères indépendants du matériel sont primordiaux. Premièrement il s’agit de l’acoustique de la pièce dans laquelle vous enregistrez. Evitez les endroits qui résonnent, typiquement une véranda car le verre réfléchit les ondes. Si vous avez le budget, investissez dans des panneaux acoustiques en mousse. Il en existe plusieurs sortes mais le principe reste le même : absorber le son pour éviter qu’il ne rebondisse. Ces panneaux doivent être placés de manière stratégique pour assurer un fonctionnement optimal. Le placement acoustique dans l’espace est un domaine vaste et je vous invite à consulter le livre cité en fin d’article pour en savoir plus.
Deuxièmement, adaptez la distance bouche-micro. Si vous êtes trop loin (50cm par exemple) on ne vous entendra pas correctement. Si au contraire vous êtes trop proche, avec la bouche quasiment collée au micro, apparaît le phénomène de proximité. Les graves sont alors amplifiés ce qui peut être gênant à l’écoute. De plus, selon la loi de la diminution d’intensité sonore en fonction de la distance, la variation de volume sera très importante dès lors que vous bougerez ne serait-ce que d’un centimètre. On voit pourtant beaucoup d’artistes chanter ou parler très proche du micro, le plus souvent il s’agit d’une erreur.
Malgré ce que vous pourrez voir ou entendre, la bonne distance bouche-micro est donc comprise entre 10 et 20 cm et vous pouvez même décaler légèrement l’axe du micro de quelques centimètres pour éviter que le flux d’air arrivant dessus ne soit trop important. A coupler avec ou sans filtre pop.
Le préampli micro
Un préampli sert à amplifier le signal envoyé par le micro car ce signal brut est trop faible. On modifie la valeur d’amplification grâce au potentiomètre du gain. Plus le gain est élevé, plus l’amplification sera forte. Attention à ne pas mettre trop de gain sous peine d’obtenir un son saturé (clipping) ! Si la sensibilité de votre micro est faible (c’est le cas avec un microphone dynamique) il faut beaucoup amplifier le signal pour qu’il soit audible. Il faut donc beaucoup de gain, aux alentours de 60 dB. Les préampli intégrés aux cartes son ont des qualités très variables en fonction du prix. Pour avoir suffisamment de gain il faut souvent mettre le prix. Renseignez-vous sur la qualité et la quantité de gain fournie par les préampli de votre carte son avant de l’acheter. Une des solutions consiste à acheter séparément un préampli micro externe permettant de booster le gain total disponible en lui ajoutant environ 30 dB. Il existe à ma connaissance 2 types de (petits) préampli externes. Le Cloudlifter (aux alentours de 160€) et le FetHead (68€). Si vous avez 4 micros, le surplus de budget engendré par des Cloudlifter ou des FetHead peut vite être problématique. A moins d’avoir vraiment de très faibles préampli intégrés à la carte son et de vouloir enregistrer de l’ASMR, je ne vous conseille pas d’acheter un FetHead ou Cloudlifter. Poussez plutôt le gain de votre carte son à fond jusqu’à obtenir un signal convenablement audible. En raison des lois de la physique, chaque appareil électronique émet un bruit propre en raison de ses composants internes. Quand un appareil est de bonne qualité, ce bruit est faible. Lorsque l’on pousse les composants dans leurs retranchements, ils atteignent leur limite et le bruit devient gênant. Le SNR (Signal Noise Ratio) est donné en dB et indique le volume d’entrée (votre voix en l’occurrence) à partir duquel le bruit propre de l’appareil est couvert. Très faible en dessous de 10 dBA, faible en dessous de 14 dBA et fort à 20 dBA. C’est la raison pour laquelle plus vous parlez fort plus vous allez couvrir le bruit généré par le préampli. Vous retrouverez une vidéo explicative (en anglais) en fin d’article.
Le pied de micro
Il est impensable de tenir votre micro à la main. A moins d’être dehors, il vous faudra obligatoirement un support pour le maintenir. Vous avez 2 possibilités. Le pied/socle de table et le bras articulé. J’ai opté pour des socles que je pose sur la table car c’est moins cher, plus facile à transporter et moins gênant visuellement. Encore une fois tout dépend de votre utilisation. Dans tous les cas je vous conseille de prendre du matériel de qualité pour éviter les mauvaises surprises. Un socle doit avoir une base lourde pour être stable. La tige peut être réglable en hauteur pour approcher ou éloigner le micro de la bouche. Le filetage doit être de bonne qualité. Un bras doit aussi être de bonne qualité et pouvoir tenir longtemps sa position même si le micro est lourd. Les vis de serrage doivent êtres solides. Le système de fixation au bureau doit également être analysé sous peine de voir votre micro par terre.
Les câbles
Attention à la qualité de vos câbles. Si vous essayez d’économiser du budget en prenant les câbles les moins chers, vous risquez d’avoir des surprises. Un mauvais câble se détériore vite et peut émettre des craquements très désagréables lors de l’enregistrement. Si vous êtes motivé, vous pouvez aussi fabriquer vos propres câbles en achetant séparément les connecteurs et les câbles au mètre. Mais je ne peux pas vous aiguiller sur ce point.
Un autre aspect des câbles est la différence entre symétrique (stéréo) et asymétrique (mono) (Balanced/Unbalanced en anglais). Un câble TRS (Tip, Ring, Sleeve) ou XLR (Xternal Live Return) sont des câbles symétriques tandis que les câbles TS (Tip, Sleeve) et RCA (ou cinch) sont asymétriques. Sans rentrer dans les détails des masses, points chauds ou froids, les câbles symétriques permettent d’éliminer les interférences dues à une grande longueur ou à des perturbateurs électriques.
Veillez juste à bien connecter des câbles stéréo dans des prises stéréo et inversement. Pour passer de l’un à l’autre, il vous faudra une DI-box ou Boîte de direct. A priori aucune utilité pour un podcast.
La carte son
La carte son est le centre névralgique de toute votre installation. C’est le hub. Elle permet de relier vos micros et vos casques à votre ordinateur pour que tout ce petit monde communique correctement. Une carte son prend donc la forme d’une “boîte” avec des prises d’entrées et de sorties (le nombre d’I/O est un critère principal !), des potentiomètres et autres commutateurs. Il existe de nombreux modèles de cartes son. Vous devez choisir en fonction du nombre d’entrées micros et de la qualité globale de la carte. Si vous comptez faire un podcast à 2, vous trouverez facilement des modèles de bonne qualité pour pas trop cher à 2 entrées XLR. Si au contraire, vous voulez être 4 ou plus, le prix augmente assez vite. Sur la carte son on retrouve (liste non exhaustive) : des entrées micros au format XLR, des entrées Line au format Jack 6.35 (le gros Jack, pas celui de votre téléphone), une sortie casque, une sortie principale qui permet de connecter des enceintes de monitoring pour le mixage, une entrée alimentation 12 ou 24V, une alimentation fantôme 48V pour les micros statiques à condensateur, un bouton de Direct Monitoring, un réglage du gain.
Alternative 1 à la carte son : l’enregistreur portable
La carte son n’est pas le seul moyen d’enregistrer un podcast. Vous pouvez aussi utiliser un enregistreur portable. Son principal atout est, comme son nom l’indique, sa portabilité. Il est petit, léger, facile d’utilisation et complet. Il possède même un micro intégré. Pour faire des micros trottoirs c’est l’idéal. Les deux marques leaders sont Zoom et Tascam. L’enregistreur portable permet de se passer d’ordinateur car il enregistre sur une carte SD. La miniaturisation a un prix et un Zoom H6 (4 entrées micro) coûte plus de 300€.
Alternative 2 à la carte son : la table de mixage
Une deuxième alternative à la carte son est la table de mixage. Elle comporte généralement beaucoup d’entrées et de sorties mais sa taille imposante et son poids ne seront pas forcément pratiques. Tout dépend de l’endroit où vous enregistrez.
Le retour audio : le casque
Je me suis longtemps demandé à quoi servaient les casques lors des enregistrements. J’ai fini par trouver la réponse. Ils permettent d’avoir un retour audio de sa voix et des autres voix enregistrées par les micros. Au début vous trouverez cela perturbant de vous entendre parler et vous n’aimerez probablement pas votre voix. C’est une question d’habitude. J’aime beaucoup le fait de se retrouver dans une sorte de bulle pendant l’enregistrement et d’entendre uniquement ma voix et celle des autres.
D’un point de vue technique, le casque possède lui aussi des caractéristiques comme la sensibilité, l’impédance ou la courbe de réponse en fréquence. Les deux dernières sont les plus importantes. L’impédance doit être en accord avec le type d’appareil que vous utilisez pour écouter. Un téléphone n’est pas en mesure de fournir une grosse quantité de courant, donc l’impédance d’un casque adéquat tourne autour des 32 Ohms. Une carte son ou une table de mixage peut à l’inverse fournir beaucoup plus de courant, choisissez une impédance d’au moins 80 Ohms.
Comme pour le micro, la courbe de réponse en fréquence indique quelles sont les fréquences valorisées ou diminuées par le casque. Pour la partie mixage, il faut un son le plus neutre possible, qui n’est pas “embelli” artificiellement. Cependant, si vous utilisez votre casque uniquement pour du podcast, la partie mixage est réduite à l’essentiel donc vous pourrez très bien mixer avec n’importe quel casque. Ce n’est pas un choix crucial, cela dépend surtout de votre budget.
Le préampli casque
Généralement, une carte son ne possède qu’une seule sortie casque. Si vous branchez plus d’un micro, il vous faudra donc un préampli casque. Ce dispositif permet de brancher simultanément plusieurs casques (4 la plupart du temps) sur la même source. Chacun peut ensuite régler individuellement le son qu’il reçoit dans son casque à l’aide d’un potentiomètre.
Le DAW
DAW signifie Digital Audio Workstation. Il s’agit du programme lancé sur votre ordinateur pendant l’enregistrement et qui permet le montage et l’exportation par la suite. Il en existe des gratuits, des payants, souvent orientés vers une application particulière (beatmaking, musique de films, musique électronique…)
Vous entendrez sûrement parler de Direct Monitoring et de latence. La latence correspond au décalage temporel entre le moment où votre signal est capté par le micro et le moment où il arrive dans vos oreilles via le casque. Sans casque il n’y a aucune latence ; vous entendez directement le son de votre voix. Cette latence est due à plusieurs paramètres. Premièrement, la conversion analogique/numérique au niveau de votre carte son provoque un premier décalage de quelques millisecondes. Ensuite votre ordinateur doit traiter le son dans le DAW. Il utilise pour cela le processeur. En fonction de la qualité de ce dernier, du nombre de pistes enregistrées simultanément et des traitements que vous affectez, cela nécessite un temps plus ou moins long. Enfin, votre ordinateur renvoie ce signal traité dans la carte son, où il est à nouveau converti (cette fois de numérique vers analogique) et transmis à votre casque via la sortie audio de la carte son, du câble et du préampli casque. Pfiou, il en faut des étapes ! Vous comprenez donc pourquoi vous pouvez obtenir une latence. Celle-ci est de l’ordre de quelques centaines de millisecondes mais c’est largement suffisant pour vous rendre fou. Une des manières de résoudre le problème est de diminuer la taille du buffer dans votre DAW. Essayer d’adopter une taille de buffer de 512 échantillons (samples) ce qui équivaut à 11-12 ms de latence. Pour mieux gérer le problème, les constructeurs de carte son ont intégré le Direct Monitoring. Pour faire simple, au lieu de faire toutes les étapes décrites plus haut, le son passe directement (d’où le nom) du micro à votre casque. Il n’y a donc aucune conversion puisque le signal reste en analogique. On parle aussi de Zero Latency. Vous trouverez la plupart du temps des commutateurs Direct Monitoring sur votre carte son. Sur celles un peu plus évoluées, on trouvera un potentiomètre permettant d’affiner le réglage. Au lieu d’avoir un tout ou rien, vous avez la possibilité de mixer les 2 signaux, le brut et celui renvoyé par votre ordinateur afin d’entendre le rendu enregistré.
Un micro enregistre en mono donc créez uniquement des pistes mono dans votre DAW.
Les 3M : Mixage, Mastering, Monitoring
Le mixage correspond au traitement du son et à l’équilibre des niveaux des différentes pistes. En production musicale c’est un critère primordial car la répartition des volumes des instruments est prépondérante pour la qualité du morceau final. Le traitement du son inclut entre autre, un égalisateur, un compresseur, un de-esser, noise gate ou de la reverb. En podcast, le mixage se résume à équilibrer le niveau de chaque voix pour éviter les déséquilibres. On peut aussi y apporter des effets comme de la compression, de l’égalisation ou un limiteur. Ces effets sont apportés par des plug-ins, de petits programmes que vous pouvez télécharger séparément et à utiliser dans votre DAW. Ces plug-ins simulent numériquement un véritable appareil analogique de traitement du son. Si certains plug-ins sont payants, il en existe de nombreux gratuits qui conviendront parfaitement pour du podcast. Attention à ne pas appliquer trop d’effets, c’est inutile pour un podcast. Avec l’expérience, en fonction de votre matériel et de l’effet recherché vous devriez trouver quels traitements appliquer. Ceci vous permet ensuite d’enregistrer un preset de vos effets dans le DAW afin de les réutiliser à chaque épisode ce qui vous fera gagner beaucoup de temps. Je peux néanmoins vous conseiller d’appliquer systématiquement un filtre coupe-bas (ou passe-haut c’est le même 😉) réglé à environ 65 Hz pour supprimer les très basses fréquences qui sont à l’origine des bruits de fond. Un égalisateur est très pratique et permet de modifier le gain de certaines fréquences. Utilisez-le avec parcimonie, quelques dB suffisent. Un compresseur permet de réduire la gamme dynamique d’un enregistrement. La gamme dynamique (dynamic range en anglais) c’est la différence entre le niveau maximal et minimal. Après avoir réglé un seuil et un pourcentage, le compresseur réduit l’écart de niveau entre les pics ce qui homogénéise l’ensemble du spectre sonore. C’est très pratique pour éviter qu’un rire un peu fort vous surprenne pendant l’écoute. Rappelez-vous, le moins de traitements possibles et meilleur sera le résultat.
Le mastering est un terme réservé à la production musicale. Il s’agit de la dernière étape avant de publier un album. L’ingénieur du son réécoute le tout et fait des ajustements entre chaque morceau pour harmoniser l’ensemble.
Le monitoring est tout simplement le contrôle du retour audio via le casque ou des enceintes. Il permet d’écouter l’enregistrement en direct ou pendant le mixage.
Le fichier audio final
Pour pouvoir diffuser votre podcast il faut l’exporter en fichier audio lisible par n’importe quel appareil. En effet, le fichier d’enregistrement brut de votre DAW est encombrant et n’est lisible que par ce DAW. A partir de l’enregistrement brut, vous exportez vers un format type mp3 ou wav. S’il existe différentes extensions de fichiers audio c’est que chacun comporte des différences. Les principales sont la compression numérique. J’ai déjà parlé de compression dans le traitement de la voix mais ce n’était pas la même. La compression numérique supprime des fréquences inaudibles ou indiquées comme trop extrêmes pour diminuer la taille du fichier final. On perd donc de l’information jugée non utile. Mais voyons comment un fichier audio numérique fonctionne. Le signal est enregistré sur forme numérique à partir du DAW sur votre ordinateur. Numérique signifie en binaire, soit une suite de 0 et de 1. Pour convertir un signal analogique en signal numérique il faut plusieurs étapes.
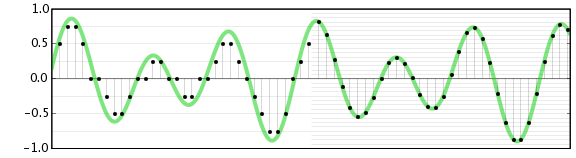
La résolution horizontale : premièrement l’échantillonnage, c’est-à-dire la fréquence à laquelle vous allez enregistrer un point du signal analogique. Les fréquences d’échantillonnage classiques sont 44.1kHz (qualité CD), 48kHz (qualité DVD), 96kHz ou encore 192kHz. Vous obtenez donc une courbe de ce type. Plus la fréquence d’échantillonnage est élevée et plus les points seront rapprochés (partie droite du schéma).
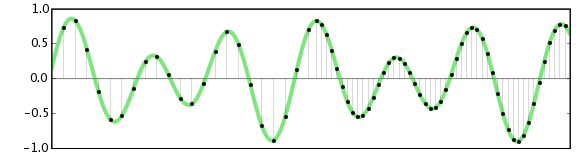
La résolution verticale : deuxièmement vous avez besoin de la profondeur de bits, autrement dit, sur combien de bits vous allez coder votre signal. 8 bits signifie que vous avez 8 possibilités de placer le point verticalement. Il existe aussi 16, 24 ou 32 bits. Comme vous pouvez le voir sur le schéma ci-dessous, lorsque l’on code sur 8 bits, on perd de l’information car la résolution verticale est faible. Le signal reconstitué ressemblera plus à un signal carré qu’une belle sinusoïde (partie droite du schéma).
Maintenant que vous avez échantillonné votre signal, il est devenu numérique. Sa qualité dépend directement de la résolution que vous avez choisi. Vous pouvez ensuite exporter votre signal numérique sous différents formats. Pour calculer la taille d’un fichier audio non compressé en Mo :
Fréquence d’échantillonnage x Profondeur de bits x Nombre de voies x Secondes
Les formats de compression les plus connus sont mp3, Ogg Vorbis, AAC, FLAC ou WAV. Certains sont lossless c’est-à-dire sans perte (WAV, FLAC) d’autres lossy, avec pertes (mp3, AAC, Ogg Vorbis). Si on préférera du lossless pour de la musique, le lossy sera largement suffisant pour de la voix (podcast). Choisissez une compression mp3 de 128 kbit/s avec une fréquence d’échantillonnage de 44,1 kHz sur 16 bits et la qualité devrait être super.
La mise en ligne
Enfin la dernière étape ! Vous avez enregistré, mixé, exporté, il est maintenant temps de diffuser votre podcast. Si vous voulez qu’il soit disponible sur la plupart des plateformes de podcast comme Apple Podcasts, Spotify, Overcast et j’en passe, il faut passer par un distributeur de podcast. Autrement dit, vous uploadez votre épisode sur une seule plateforme (celle qui host votre podcast) et c’est elle qui va s’occuper de la transmettre aux autres. La plupart de ces plateformes de diffusion sont payantes et limitées. Leurs versions gratuites sont encore plus limitées. Si vous cherchez une bonne solution gratuite je vous conseille Anchor. Tout est gratuit et illimité. Ils ont récemment été rachetés par Spotify ce qui peut expliquer cette gratuité sans limites. Tout le processus est très simple et votre podcast sera diffusé correctement.
Une solution complémentaire consiste à le mettre sur YouTube. Il faudra en revanche convertir votre fichier mp3 ou wav en format vidéo c’est-à-dire mp4 par exemple. Je vous conseille aussi de rajouter une image fixe avec le titre afin d’éviter un écran noir. Pour cela, je vous recommande d’utiliser ffmpeg. C’est un programme qui s’utilise depuis le terminal de votre ordinateur donc il n’y a pas d’interface graphique. Vous devez mettre le fichier audio (mp3, wav, flac, aac…) et l’image (jpg, png, jpeg…) dans le même dossier. Ouvrez ensuite le terminal et assurez-vous d’être dans le bon dossier. Tapez ensuite cette ligne de commande en remplaçant les $1, $2 et $3 par les noms de vos fichiers.
ffmpeg -loop 1 -i $1 -i $2 -c:v libx264 -tune stillimage -c:a aac -b:a 192k -pix_fmt yuv420p -shortest "$3.mp4"
Et si vous êtes déter’ vous pouvez créer un script pour éviter de retaper la ligne de commande ffmpeg à chaque fois.
#!/bin/bash
if [ $# -ne 3 ]; then
echo -e "Usage: \t$(basename $0) image audio result_filename"
exit 1
fi
ffmpeg -loop 1 -i $1 -i $2 -c:v libx264 -tune stillimage -c:a aac -b:a 192k -pix_fmt yuv420p -shortest "$3.mp4"
Vous pouvez ensuite mettre en ligne sur YouTube !
Mon matos
Je ne suis sponsorisé par aucune marque et je ne tiens pas à faire de pub mais je pense que ça intéresse les lecteurs, notamment ceux qui ont envie de se lancer, de savoir quel matériel j’utilise. Bien évidemment, il s’agit d’un exemple parmi une infinité, vous n’êtes pas obligé de prendre le même, tout dépend de votre budget et de ce que vous voulez en faire.
-
Carte son : Behringer U-Phoria UMC404HD
-
Micros : RODE Podmic avec bonnette WS2
-
Pieds de micro : K&M 232BK
-
Casque : Beyerdynamic DT-770 Pro version 80 Ohms
-
Câbles Cordial : CTM et CPM pour l’XLR et CFU pour les doubles Jack 6.35
-
Preamp casque : LD System HPA4
-
Enceintes de monitoring : PreSonus Eris 3.5
-
DAW : PreSonus Studio One
Quelques définitions de termes techniques
Headroom : Réserve de volume disponible avant d’atteindre la distorsion
Théorème de Nyquist-Shannon : Pour reconstruire parfaitement un signal (ici audio), la fréquence d’échantillonnage doit au moins être le double de la largeur de bande du signal échantillonné. En théorie cela signifie qu’il ne faudrait jamais enregistrer en dessous de 40 kHz
Effet de proximité (proximity effect) : augmentation des graves et des bas-médiums lorsque l’on parle très proche du micro
Ecrêtage (clipping) : Distorsion du son en raison d’un signal trop fort (plosive, cri…)
Pour en savoir plus
Le site et forum Audiofanzine et leur chaîne YouTube
Les chaînes YouTube de Julian Krause et de Joe Gilder
Le grand livre du home studio de Franck Ernould et Denis Fortier aux éditions Dunod
Les sites d’aides de PreSonus et de Focusrite
Les docs constructeur et modes d’emploi (on y apprend plein de choses !)